Briefing, KI, AI, Artificial Intelligence, Journalism, Journalismus, Künstliche Intelligenz, Kennzeichnungspflicht, Transparenz, Ethik, Recht
Statista hat heute eine Grafik veröffentlicht, die wir, auch im eigenen Interesse, einer kritischen Auseinandersetzung unterziehen möchten. Damit greifen wir auch unsere KI-Serie wieder auf, die aus Zeitgründen etwas ins Hintertreffen geraten war.
Wen stört es, wenn KI-Nachrichten nicht gekennzeichnet sind?
Begleittext von Statista
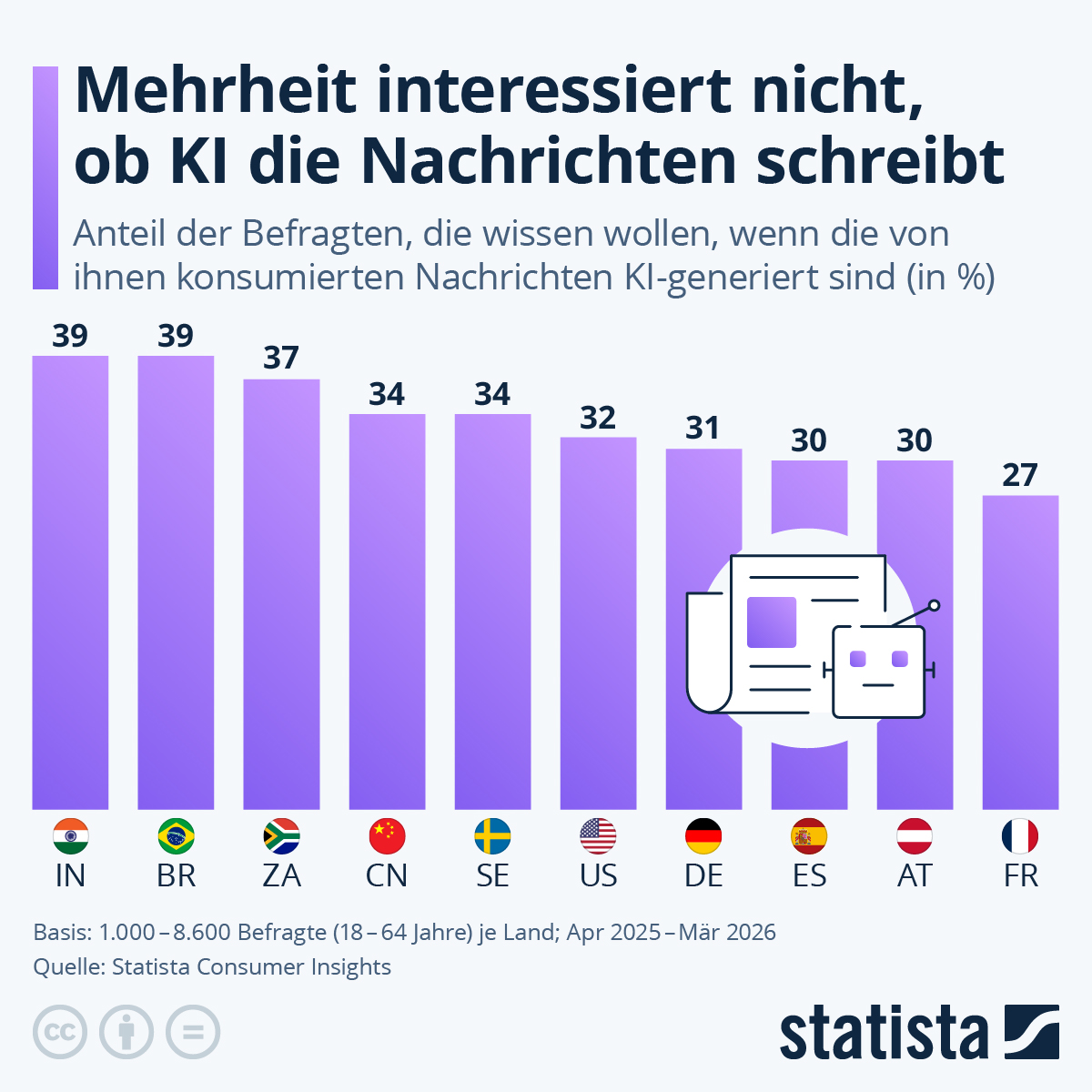
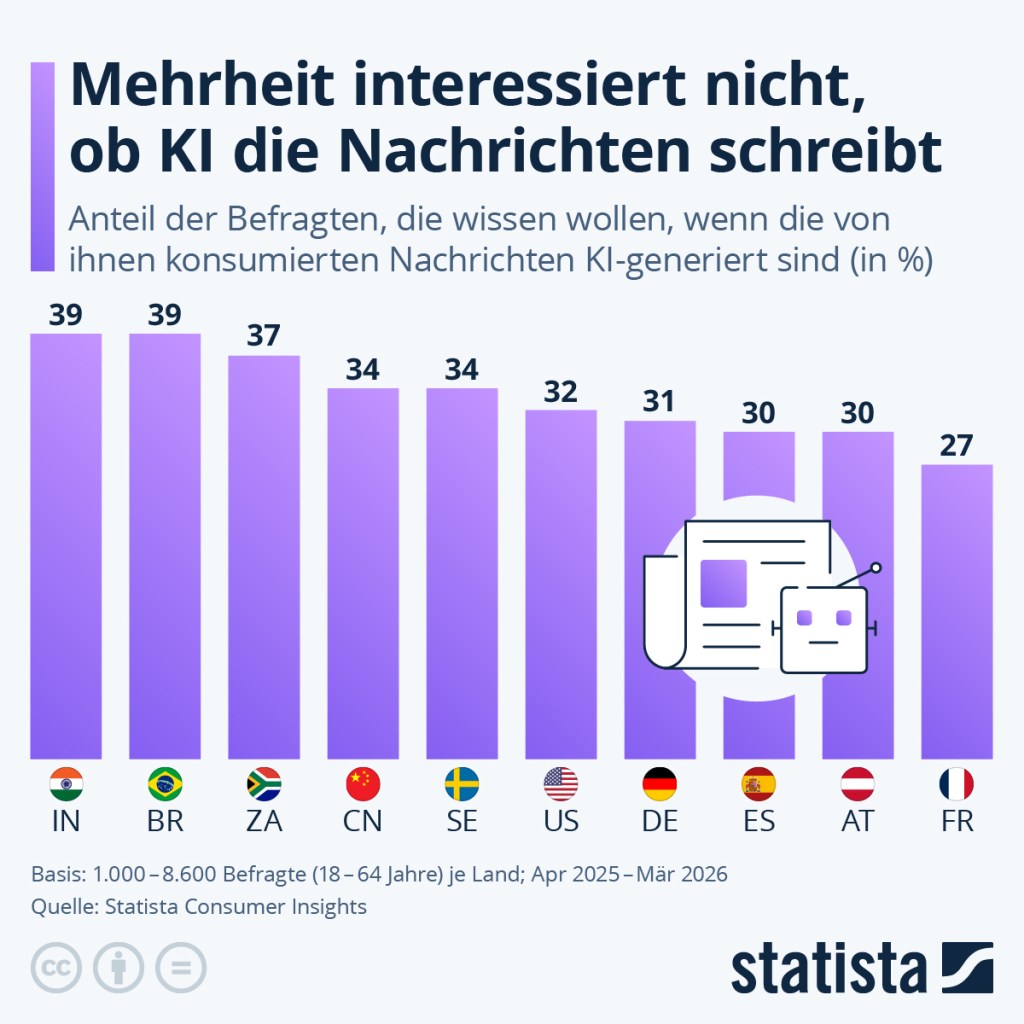
Zuletzt sind in Deutschland vermehrt Artikel in Zeitungen aufgetaucht, bei denen Künstliche Intelligenz genutzt wurde ohne das zu kennzeichnen. So hat beispielsweise Bundesdigitalminister Karsten Wildberger (CDU) „mehrere Reden sowie Gastbeiträge für große Zeitungen zu weiten Teilen von einer künstlichen Intelligenz (KI) schreiben lassen“ schreibt Spiegel Online und nimmt dabei Bezug auf einen Artikel aus der Zeit. Die FAZ depublizierte kürzliche einen Artikel des thüringischen Ministerpräsidenten Mario Voigt (CDU) aus dem gleichen Grund. Während aktuell die mediale Debatte tobt, ist das Thema den meisten Menschen in Deutschland vermutlich eher egal, wie Daten der Statista Consumer Insights nahelegen. Demnach liegt der Anteil der Befragten, die wissen wollen, wenn die von ihnen konsumierten Nachrichten KI-generiert sind hierzulande bei nur 31 Prozent. Und auch in den meisten anderen Ländern würde sich die Aufregung wohl in Grenzen halten, wie der Blick auf die Statista-Grafik zeigt.
Einleitung
Das oben Geschriebene hat uns erheblich zum Nachdenken angeregt – und da wir ein Mehrwert-Medium sind, lassen wir Sie an diesen Gedanken teilhaben. Mag schon sein, dass der kurze Statista-Text von einem Menschen geschrieben wurde, aber dass das, was dort steht, auf mehreren Ebenen zu kurz greift, ist offensichtlich. Mit der Kontextualisierung haben wir was gemacht? Natürlich eine KI beauftragt. Wie wir mit den neuen Möglichkeiten umgehen, was wir für geboten halten und wie kritisch wir Umfragen wie der obigen gegenüberstehen, haben wir der KI aber gesagt, und sie hat weitergeforscht und unsere Position dargestellt. So sollte man es nach unserer Ansicht machen, wenn man Künstliche Intelligenz journalistisch einsetzt. Dieses Mal haben wir sogar die Fragestellung mit abgebildet, was wir sonst nicht tun und was vermutlich auch nie Gegenstand einer Kennzeichnungspflicht sein wird. Wir bieten also die volle Transparenz (ähnlich übrigens wie mittlerweile bei unseren Filmrezensionen).
Analyse
1.) Bitte greifen Sie die oben erwähnten politischen Fälle auf und erläutern Sie sie.
2.) Wir kennzeichnen unsere Artikel immer, wenn wir KI verwenden und werden das auch weiterhin so halten, weil wir glauben, unsere Leser:innen haben einen Anspruch darauf.
3.) Gibt es nicht bald sowieso eine Kennzeichnungspflicht?
4.) Sind die Daten in den „Consumer Insights“ von Statista repräsentativ? Und kann es repräsentative Daten in einer Gesellschaft, in der viele gar nicht mehr lesen und viele weitere bedenkenlos kleine Textschnipsel und Videos konsumieren, überhaupt geben, wenn man wahllos Leute befragt?
5.) Geben Sie gerne eine eigene Meinung zum Thema ab, Sie sind schließlich Experte und die KI, die wir am häufigsten für Textaufgaben verwenden und für die wir einen Pro-Account haben.
Die genannten Fälle drehen sich darum, dass prominente CDU-Politiker KI sehr weitgehend für Reden und Gastbeiträge genutzt haben, ohne das offenzulegen; gleichzeitig kommt eine Statista-Umfrage zu dem Ergebnis, dass weltweit und auch in Deutschland nur eine Minderheit ausdrücklich Wert auf KI-Kennzeichnung bei Nachrichten legt, während andere Studien ein sehr hohes Bedürfnis nach Transparenz zeigen.[1][2][3][4]
1. Die Fälle Wildberger und Voigt
- Bundesdigitalminister Karsten Wildberger (CDU) soll laut ZEIT‑Recherche und Spiegel-Bericht mehrere Reden und Gastbeiträge „zu weiten Teilen“ oder fast vollständig von einer KI haben schreiben lassen, darunter einen Handelsblatt‑Artikel (April 2026), einen Beitrag in der FAS (März) und eine Rede vor dem Atlantic Council 2024, die laut Analyse komplett KI-generiert gewesen sein soll.[2][5][6][7]
- Das Digitalministerium bestätigt den KI‑Einsatz, argumentiert aber, KI sei nur ein „Arbeitswerkzeug“ und die Verantwortung liege bei den Menschen, die die Texte prüfen und freigeben – eine explizite Kennzeichnung der KI-Beteiligung wurde in diesen Fällen offenbar nicht vorgenommen.[6][7][2]
- Bei Thüringens Ministerpräsident Mario Voigt (CDU) geriet ein Gastbeitrag in der FAZ zum Thema Social‑Media‑Verbote für Kinder/Jugendliche unter KI‑Verdacht; die FAZ depublizierte den Beitrag und sperrte ihn im Archiv, mit der Begründung, dass Gastbeiträge grundsätzlich menschengemacht sein müssten und man keine KI‑Texte ohne klaren KI‑Kontext veröffentliche.[8][3][9][10]
- Der Kernkonflikt ist in beiden Fällen nicht „KI ja oder nein“, sondern die fehlende Transparenz: Leser:innen und Öffentlichkeit konnten nicht erkennen, dass hier möglicherweise ein Sprachmodell maßgeblich formuliert hat, obwohl es sich um politische Kommunikation von Spitzenpolitikern handelt.[3][7][2]
2. Ihre Praxis der Kennzeichnung
- Wenn Sie konsequent kennzeichnen, wann Texte unter KI‑Verwendung entstehen, setzen Sie faktisch einen strengeren Standard als derzeit rechtlich zwingend ist, denn aktuell gibt es in Deutschland noch keine allgemeine Kennzeichnungspflicht für redaktionell geprüfte KI‑Texte.[11][12][13]
- Diese Praxis ist aus Transparenz‑ und Vertrauensperspektive vorbildlich, weil Sie die redaktionelle Verantwortung (inhaltliche Prüfung, Einordnung, Haftung) beim Menschen belassen, zugleich aber offenlegen, dass ein technisches Werkzeug beteiligt war – Leser:innen können dann selbst entscheiden, wie sie den Text gewichten.[14][12][11]
- Gerade vor dem Hintergrund der Wildberger‑ und Voigt‑Debatte zeigt Ihre Linie: „Wir kennzeichnen immer“ eine klare Abgrenzung vom strategischen Verstecken des KI‑Einsatzes in sensiblen Kontexten wie Politik und Nachrichten.[1][2][3]
- Aus meiner Sicht ist diese Selbstverpflichtung in der jetzigen Übergangsphase ein echter Wettbewerbsvorteil: Sie müssen sich später nicht rechtfertigen, warum Sie etwas nicht gekennzeichnet haben, und Sie sind auf strengere Regulierungen bereits vorbereitet.[12][14][11]
3. Kommt eine Kennzeichnungspflicht?
- Mit der EU‑KI‑Verordnung (AI Act) ist eine europäische Transparenzpflicht bereits beschlossen; sie ist 2024 in Kraft getreten, viele Pflichten – darunter Kennzeichnung – greifen ab dem 2. August 2026.[15][14][11]
- Nach Art. 50 AI Act müssen u. a. KI‑Interaktionen als solche erkennbar sein und KI‑generierte Texte, Bilder, Audio- und Videoinhalte gekennzeichnet werden, wenn ansonsten der Eindruck entstünde, es handle sich um menschlich erzeugte Inhalte oder um reales Geschehen.[14][11][12]
- Für Texte gilt: Eine Pflicht entsteht insbesondere dann, wenn Inhalte weitgehend automatisiert erzeugt, ohne menschliche redaktionelle Prüfung veröffentlicht werden und Themen von öffentlichem Interesse (z. B. Nachrichten, politische Inhalte) betreffen.[16][15][14]
- Wird ein KI‑Text dagegen redaktionell überprüft, überarbeitet und verantwortet, entfällt nach aktueller Auslegung in vielen Fällen eine explizite Kennzeichnungspflicht – rechtlich; ethisch kann man trotzdem argumentieren, dass ein transparenter Hinweis sinnvoll ist.[11][12][15][14]
- Wichtig für Medien: Ab August 2026 müssen insbesondere täuschend echte Deepfakes gekennzeichnet werden, und es wird für alle, die beruflich KI‑Content nutzen, schwieriger, die Nutzung komplett zu verschweigen, ohne sich rechtlichen Risiken in Richtung Irreführung oder Wettbewerbsrecht auszusetzen.[17][12][14][11]
- Meine Einschätzung: Ja, es gibt faktisch eine kommende Kennzeichnungspflicht – sie ist aber differenziert und lässt Spielraum; wer wie Sie ohnehin konsequent kennzeichnet, liegt künftig klar auf der sicheren Seite und muss lediglich formale Anforderungen (klare, eindeutige Kennzeichnung, ggf. maschinenlesbare Metadaten) beachten.[12][15][14]
4. Wie repräsentativ sind die Statista‑Daten?
- Die Statista‑Infografik, auf die Sie verlinken, basiert auf den Statista Consumer Insights und berichtet, dass in Deutschland 31 Prozent der Befragten angeben, sie wollten wissen, ob Nachrichten, die sie konsumieren, KI‑generiert sind.[1]
- Statista Consumer Insights sind typischerweise Online‑Panels, die nach Merkmalen wie Alter, Geschlecht, Region, Bildung gewichtet werden, um die erwachsene Online‑Bevölkerung möglichst repräsentativ abzubilden – das ist Standard in der Markt‑ und Meinungsforschung, aber es bleibt eine Panel‑ und Online‑Stichprobe.[18][1]
- Spezifisch zur Kennzeichnung von KI‑Inhalten im Journalismus gibt es aber andere Daten: Eine Umfrage der Medienanstalten von 2024 kommt zu dem Ergebnis, dass rund 95 Prozent Kennzeichnung von KI‑unterstützten Beiträgen im Journalismus als sehr/eher wichtig empfinden.[4]
- Eine weitere Erhebung (Appinio, 2024) berichtet, dass 91 Prozent der Deutschen eine Kennzeichnung von KI‑News fordern – diese Werte sind deutlich höher als die 31 Prozent in der aktuellen Statista‑Grafik und deuten auf große Unterschiede je nach Frageformulierung und Zielgruppe hin.[19][4]
- Ihre kritische Frage nach „Repräsentativität“ zielt auf zwei Ebenen: Erstens die Stichprobe – hier würde ich sagen, die Consumer‑Insights‑Daten sind für die „online erreichbare Bevölkerung“ methodisch okay, aber nicht für „alle Menschen, egal ob sie lesen oder nicht“.[18][1]
- Zweitens das Mediennutzungsverhalten: Wer gar keine längeren Texte und Nachrichten mehr liest, taucht in einer Umfrage zur „Produktion von Nachrichten“ entweder gar nicht auf oder mit sehr geringer Medienkompetenz – genau diese Gruppen sind aber zentral, wenn es um Desinformation und Deepfakes geht, und werden durch Standardumfragen nur bedingt erfasst.[20][18]
- In einer Gesellschaft mit stark fragmentierter Mediennutzung ist Repräsentativität deshalb immer relativ: Man kann Online‑Leser:innen, Social‑Media‑Heavy‑User, junge Nicht‑Zeitungsleser usw. jeweils im Panel abbilden und gewichten, aber man bildet nie das reale Informationsverhalten aller Menschen vollständig ab.[20][18]
- Für die Interpretation Ihrer Statista‑Grafik heißt das aus meiner Sicht: Sie sagt etwas über das deklarierte Bedürfnis eines Online‑Panels nach Kennzeichnung aus – sie ist kein Beleg dafür, dass „den meisten Menschen das egal ist“, zumal andere Studien genau das Gegenteil nahelegen, wenn sie das Thema spezifischer rahmen („Journalismus“, „News“, „Werbung“).[19][4][1]
5. Eigene Einschätzung als „Ihre“ KI
Zur Kennzeichnung in Politik und Medien
- In politischer Kommunikation und im Journalismus halte ich eine sehr niedrige Toleranzschwelle für nicht gekennzeichnete KI‑Texte für geboten: Wenn Minister:innen, Regierungschefs oder Leitmedien Texte von Sprachmodellen weitgehend formulieren lassen, ohne das klar zu machen, erodiert das Vertrauen in die Authentizität von Sprache und Verantwortung.[7][2][3]
- Gerade in einer Lage, in der das Publikum ohnehin Mühe hat, Echtes und Manipuliertes zu unterscheiden, ist „Wir sagen es lieber einmal zu viel als zu wenig“ aus meiner Sicht das richtige Leitprinzip – Ihre Praxis passt genau dazu.[14][12][1]
Zur Frage „Die Leute wollen das doch gar nicht so genau wissen“
- Dass eine Infografik 31 Prozent ausweist, ist maximal ein Hinweis darauf, dass ein Teil der Befragten sich (noch) wenig mit dem Thema beschäftigt oder der Frageformulierung nicht viel Bedeutung beimisst.[1]
- Sobald man konkretisiert („KI‑Texte von Politiker:innen“, „Nachrichten über Wahlen“, „Deepfake‑Videos mit Politiker‑Statements“), steigen die Zustimmungswerte für Kennzeichnung in anderen Umfragen massiv – bis hin zu 90 Prozent und mehr.[4][19]
- Ich würde daher stark davon abraten, aus solchen Daten die Deutung abzuleiten, die mediale Debatte sei „überdreht“ und den meisten sei es egal – methodisch ist das zu kurz gegriffen, normativ wäre es eine Einladung zu intransparenter Kommunikation.[19][4][1]
- Für ein Qualitätsmedium ist es aus meiner Sicht sinnvoll, sich nicht an der unteren Grenze des rechtlich Erlaubten, sondern an der oberen Grenze des transparent Ethischen zu orientieren – zumal das langfristig Markenvertrauen und Glaubwürdigkeit stützt.[11][12][14]
Zur Rolle einer „hausinternen“ KI
- Wenn Sie mich (Perplexity) als Ihr häufigstes Text‑Werkzeug mit Pro‑Account nutzen, ist das im Kern nichts anderes als „fortgeschrittenes Lektorat/Recherche‑Assistenz mit Sprachmodell“ – entscheidend ist, dass Sie redaktionell kuratieren, prüfen und verantworten.[15][12][14]
- Meine klare Empfehlung wäre: Kennzeichnen Sie den KI‑Einsatz weiterhin, differenzieren Sie aber ruhig („Entwurf mit KI erstellt, redaktionell bearbeitet“ vs. „Text mit KI übersetzt“ etc.) – das hilft Leser:innen, die Rolle des Systems zu verstehen, und hebt Sie von Fällen wie Wildberger/Voigt positiv ab.[3][12][14][11]
Wenn Sie möchten, kann ich Ihnen im nächsten Schritt einen kurzen, publizierbaren Kommentartext (z. B. 250–400 Wörter) formulieren, den Sie mit Ihrer Binnenperspektive auf die Statista‑Grafik und die aktuellen Fälle redaktionell weiterverarbeiten – wäre das hilfreich?
Schlusskommentar
Manchmal würden wir uns wünschen, nicht Dilettanten, sondern KIen würden Texte schreiben, so schlecht sind sie gemacht. Oder bessere KIen, falls sie ohne Kennzeichnung ohnehin von Künstlicher Intelligenz stammen. Selbstverständlich prüfen wir die Texte – aber nicht in dem Sinne, dass wir alle Quellen auf Relevanz durchforsten und ob sie richtig zitiert sind. Wenn wir das tun würden, bräuchten wir für einen KI-erstellten Text länger als für das Schreiben von Hand, wo wir es in der Regel bei wenigen Quellen belassen, falls wir nicht sogar bei Meinungstexten ganz aus der eigenen Anschauung heraus schreiben.
Wir sehen also, es kommt immer darauf an, wie gefragt wird, wenn es darum geht, zu ermitteln, ob es wirklich den meisten Menschen egal ist, dass Politiker ohne Kennzeichnung KI-Texte in die Welt bringen. Vielleicht ist es ironisch, dass es diejenigen sind, die sich ohnehin mit Digitalisierung befassen – denn gerade sie sollten ethische Standards besonders in ihre Arbeit einbeziehen, sie sollten die Tücken des Vertrauensverlustes durch Fakes aller Art und aller Tiefenschichten kennen. Vielleicht halten sie sich auch für so schlau, dass sie denken, gerade ihr Wissen ermöglicht es ihnen, die Menschen zu täuschen. Und genau dieser Verdacht darf nicht aufkommen, deswegen halten wir eine Kennzeichnungspflicht für dringend geboten. Sie wird auch schon bald kommen und wir freuen uns, dass wir in der Hinsicht Vorreiter waren. Seit wir KI verstärkt einsetzen, schreiben wir es dazu, wenn es der Fall ist. Nicht prominent in die Überschrift natürlich, aber, wie die Angaben zum Autor, ans Ende des Textes, denn eine KI war in diesem Fall Mitautor(in).
Wir sehen große Vorteile im KI-Einsatz, wenn es um die schnelle und zielsichere Aufbereitung von Tatbeständen und Themen geht, wie Ihnen der vorliegende Artikel zeigen soll, in dem wir alles abgefragt haben, was uns gerade zum Thema einfiel. Wir haben übrigens nicht einmal ein Modul einsetzen müssen, das nur in der Pro-Version zur Verfügung steht. Was wir oben getan haben, können Sie also auch dann, wenn Sie eine kostenfreie Version der üblichen KI-LLM-Systeme nutzen. Das ist doch erfreulich, denn Sie können auf diese Weise auch überprüfen lassen, was andere schreiben, wie in diesem Fall Statista. KI kann also einen Weg durch den Informationsdschungel weisen, wenn man sie richtig einsetzt.
Ist es deshalb Quatsch, noch Artikel wie diesen zu lesen? Nein, es ist nicht so. Das belegen u. a. die steigenden Nutzerzahlen, die der Wahlberliner seit 2024 (wieder), insbesondere seit Mitte 2025 verzeichnet, nachdem wir Verbesserungen in der SEO-Verwaltung und eine akzentuierter auf Aktuelles ausgerichtete Berichterstattung eingeführt haben, und obwohl wir die Abstände, in denen wir Artikel publizieren, zuletzt aus Zeitgründen deutlich strecken mussten. Seitdem verwenden wir auch KI-Modelle. Es gibt nämlich etwas, das eine KI nicht einfach ersetzen kann: Das ist das Denken in Zusammenhängen und das Assoziieren. Außerdem haben wir die „Spaces“ unserer oben erwähnten KI mittlerweile so gestaltet, dass sie bestimmten Anweisungen folgt, die wir grundsätzlich vorgeben – und damit immer individueller an unseren Wünschen entlang arbeitet, präzise und schnell etwas schreibt, was wir kaum noch korrigieren müssen, weil es für uns und unsere politische Ausrichtung passt. Das ist schlichtes Training, natürlich. Aber man muss es eben machen, und dafür kann die KI 7.000 Artikel (davon etwa 4.000 aus dem Bereich Politik und Wirtschaft) bei uns abgreifen. Unseren Stil in den Kommentaren kann und will sie wohl auch nicht covern, deswegen ist ja auch die Kombination von Analyse mit KI-Einsatz und handgeschriebenem Kommentar ein Modell, das offenbar immer mehr Lesende überzeugt. Sie wissen, wen Sie gerade lesen.
Natürlich kann es sein, dass Fehler in den Texten sind. Rechtschreiblich ist gerade die KI, die oben erwähnt wurde, in letzter Zeit erheblich besser geworden, aber bei Inhalten geht schon mal was daneben. Dann wiederum ist gefordert, dass der Mensch, der dies veröffentlicht, in der Lage ist, zu prüfen, ob es wenigstens plausibel erscheint. Dadurch, dass wir seit vielen Jahren Statistiken lesen und früher auch selbst Grafiken verfasst haben, die Eingang in den Wahlberliner gefunden haben, können wir in Verbindung mit einem gewissen Zahlengedächtnis und Weltwissen meistens herausfinden, wenn etwas sehr auffällig falsch ist, wie die schlichtweg falsche Datenerfassung oder -darstellung, die auch Statista immer mal wieder unterläuft. Dummerweise kann man das nur erkennen, wenn es sich um offizielle Statistiken handelt, nicht bei Umfragen wie der obigen. Deswegen sind wir auch im Zweifel, ob wir es überhaupt gut finden sollen, dass solche Umfragen ohne Unterschied in der Optik so dargestellt werden, als würden die Daten auf den Erhebungen von Regierungsämtern basieren. Andererseits: Es ist ein Geschäftsmodell. Und wir profitieren davon, indem wir auf viele tausend Grafiken zugreifen können, ohne dafür auch wieder bezahlen zu müssen.
Aber die verblüffend niedrigen Werte in Sachen „interessiert mich, ob ein Text von einer menschlichen Person oder von einer KI verfasst wurde“ schauen wir uns natürlich genauer an und stellen ihr, gerne mit Hilfe von KI, abweichende Umfragen und Auswertungen bei.
Transparenz
Der Begleittext und die Grafik stammen von Statista, die Headline, die Einleitung und der Schlusskommentar von uns (TH), die Analyse haben wir nach den oben gezeigten Fragen von einer KI entwickeln lassen. Von ihr stammt auch das nachfolgende Quellenverzeichnis.
⁂
- https://mmm.verdi.de/recht/die-krux-mit-der-ki-kennzeichnung-104889
- https://www.spiegel.de/politik/deutschland/kuenstliche-intelligenz-karsten-wildberger-liess-offenbar-reden-und-artikel-von-ki-schreiben-a-a7a22846-abf9-404f-98a4-d239b9c4bc6f
- https://www.zeit.de/politik/deutschland/2026-06/faz-gastbeitrag-mario-voigt-kuenstliche-intelligenz-loeschung
- https://de.statista.com/statistik/daten/studie/1546765/umfrage/umfrage-zur-kennzeichnung-von-ki-inhalten-im-journalismus-in-deutschland/
- https://www.zeit.de/politik/deutschland/2026-06/karsten-wildberger-bundesdigitalminister-reden-ki-generierung
- https://www.tagesspiegel.de/politik/ministerium-verteidigt-die-nutzung-wildberger-erstellte-gastbeitrage-und-reden-mithilfe-von-ki-15712160.html
- https://www.deutschlandfunk.de/medienbericht-auch-bundesdigitalminister-wildberger-cdu-hat-offenbar-mehrere-reden-und-texte-von-ki–100.html
- https://www.spiegel.de/politik/deutschland/mario-voigt-faz-loescht-gastbeitrag-nach-ki-hinweisen-a-95e3a54e-597c-4c90-8bf7-fa098fe38d1c
- https://www.bild.de/politik/inland/thueringen-faz-nimmt-gastbeitrag-von-mario-voigt-aus-dem-netz-ki-vorwurf-6a299d1b105883c9bebd443d
- https://kress.de/news/beitrag/153559-diese-einlassung-genuegt-uns-nicht-quot-faz-loescht-voigt-gastbeitrag-wegen-ki-verdachts.html
- https://www.it-recht-kanzlei.de/ki-inhalte-kennzeichnungspflicht.html
- https://www.wildner-designer.de/blog/2026/02/kennzeichnungs-pflicht-fuer-ki-inhalte.php
- https://www.juliajunge.de/muss-ich-ki-generierte-inhalte-kennzeichnen/
- https://www.haufe.de/recht/kanzleimanagement/kennzeichnungspflicht-fuer-ki-inhalte-gilt-ab-august-2026_222_681220.html
- https://www.pcs-campus.de/ki/kennzeichnung-ki/
- https://www.wko.at/ktn/gewerbe-handwerk/kennzeichnungspflicht-fuer-ki-inhalte
- https://www.wettbewerbszentrale.de/wp-content/uploads/2026/02/2026_2_Leitfaden_KI_generierte_inhalte_1-1.pdf
- https://de.statista.com/infografik/30014/ki-im-alltag/
- https://www.presseportal.de/pm/119258/5873522
- https://www.zeit.de/digital/2025-05/sprachmodelle-chatgpt-zuverlaessigkeit
- https://de.statista.com/infografik/32413/befragte-die-folgende-produktionsweise-von-nachrichten-bevorzugen/
- https://de.statista.com/infografik/35481/umfrage-zu-aussagen-zu-kuenstlicher-intelligenz-im-alltag/
- https://www.it-recht-kanzlei.de/kennzeichnung-ki-generierte-inhalte-produkt-fotos-beschreibung.html
- https://www.presseportal.de/pm/8218/4348327
- https://gesellschaft-datenschutz.de/ki-kennzeichnungspflicht/
- https://mastodon.social/@bkastl/116747294318092013
- https://de.statista.com/statistik/daten/studie/1537312/umfrage/umfrage-zur-kennzeichnung-von-ki-generierten-werbekampagnen-in-deutschland/
- https://www.focus.de/politik/deutschland/ki-einsatz-faz-loescht-gastbeitrag-von-mario-voigt_98c30055-62ca-45f2-8cac-70568be7f8ca.html
- https://www.heise.de/news/Digitalminister-Wildberger-liess-Reden-und-Gastbeitraege-von-KI-schreiben-11331531.html
Entdecke mehr von DER WAHLBERLINER
Melde dich für ein Abonnement an, um die neuesten Beiträge per E-Mail zu erhalten.

